EMOS Framework: Functional Testing Based on GUI-Modelling
Dean Rajovic
EMOS Computer Consulting GmbH
Oskar-Messter-Str. 25
85737
Ismaning by
© 2001 EMOS Computer Consulting GmbH
ABSTRACT
In this paper we discuss the role of GUI-modelling in the area of functional testing and present a framework for the development and execution of automated functional tests based on such modelling. The main issues addressed by the framework are: rapid test development, intensive involvement of non-technical personnel in test automation and maintainability of the test environment that scales well for large systems.
The main features of our approach to GUI-modelling are reducing GUI operations to their SET (enter) and CHK (verify) alternatives and capturing the navigation as an intrinsic part of the test description. Through a simple linkage concept, an extremely high level of reusability of test data and test code is achieved.
The technical implementation is realised with the popular test tool WinRunner® from Mercury Interactive and is available under the Lesser General Public Licence (LGPL). The concept is applicable to practically any application designed for intensive data maintenance via "standard" GUI objects. It has been successfully applied to several highly complex test automation endeavours in branches like insurance, banking and telecommunications.
KEYWORDS:
testing, test automation, functional testing, test framework, WinRunner
1 INTRODUCTION
There are many challenges in testing
complex systems. Automating tests in such environments reduces some of them but
introduces additional ones. Tests which are suitable for manual testing are not
necessarily suitable for test automation (provided they have been specified/written at all). The sheer amount of possible test
cases can scare even the most experienced test manager/specialist. Especially
when such tests are to be carried out with hopelessly understaffed test teams
and within ridiculous time frames...[5] Organising numerous test artefacts into
a maintainable complex that survives long enough to prove its usefulness is a
very challenging task [3, 4, 6, 7, 8].
The most common approach to functional testing is by exercising the application through its user interface. Automation of functional tests simply cannot ignore the GUI-oriented test tools from vendors such as Mercury Interactive, Rational, Segue, Compuware, etc. Although these tools are capable of implementing very complex approaches, advanced users seem to be left alone to discover the advanced techniques on their own.
It does not take much browsing through the literature or in the Internet to discover that many people found their own solutions [1, 2, 3, 8]. These solutions always seem to follow the same path: from capture/replay (record/playback) via scripting and data-driven testing to test frameworks. Due to the lack of firm theoretic fundaments that could guarantee their universal applicability (which is probably the reason none of the leading tool vendors offer such frameworks), these frameworks pair their own testing methodology with the technical support for it. Nevertheless, they all try to solve the same problem: make the test automation more effective and more efficient.
When it comes to testing via the application's user interface, these frameworks appear to use the same approach: each models the test design in its own way and provides an interface to one (or more) standard GUI-centred test tool that executes the tests. The most influential test framework so far is probably the CMG's TestFrame® [1]. This is the powerful framework based on a keyword-driven separation (in their terminology: "action words") between the test data ("test clusters") and the test scripts. The most important common property of almost all of the approaches at this maturity level is the separation of the test data from the test scripts. The more advanced the separation, the more advanced the concept (e.g. simple data-driven versus keyword-driven approach).
2 THE “BUSINESS CASE SYNDROME”
Advanced concepts attempt to express the test cases in terms of business processes: the high-level abstractions that hide their actual implementation as much as possible. The promised benefits of such "business modelling" include the independence of the particular user interface, increased comprehension to non-programmers and improved requirements/design coverage.
However the separation of scripts and data has its costs. The closer we get to the "business language", the bigger the gap to the actual test implementation. Under the premise that we attempt to ignore the particular user interface, it becomes increasingly more difficult to find reusable code patterns that relate to such "business language". Such patterns however are fundamental to bridging the gap between business models and their implementation.
Business processes are rarely simple. The problem is often "solved" by chunking big transactions into smaller parts and/or by reducing the information that has actually been tested. We often see functions like enter_xxx(...), delete_xxx(...) and modify_xxx(...) accompanied with the claim they test the given business processes. The questions is whether they really do.
The test code must be flexible. Among other things it should be able to enter and check valid situations, provoke errors, take alternative, unusual or illegal paths through the application, handle dynamic (context-sensitive) parts of the application and check the reaction of the application at many different places. The purpose of this code is testing. It should serve as a "playground" for implementing test ideas. It should be able to mirror the behaviour of the real human (and destructive) tester as much as possible. This cannot be achieved with a code in which many decisions are hard coded. When an alternative "route" is needed or when things get changed (as they inevitably do with testing) one must make adaptations somewhere to get the code working. Questions that arise are:
· Where to adapt?
· Who can adapt it?
· How much does it cost (time/money) to adapt?
A test automation expert (test programmer, tool specialist) is permanently forced to make decisions about what information to make public (i.e. make it a "business case") and what information to "bury" into the test scripts. The trade off is that the information which is made public can (usually) be changed by non-programmers (domain experts, end users, testers) whereas the "buried" information requires programming expertise to change. Simple changes in the application's user interface can easily affect plenty (hundreds) of test cases if the information is exposed or only a few lines of code if the information is hidden. Obviously, a careful balance must be found. However, it is a gamble! More often than we would like, changes affect both exposed or hidden information regardless of our "clever" balancing. Those who know the tricks of test automation will appear to be "luckier" than the others.
The main benefit of test frameworks is in providing guidelines for those who use them (test designers, test programmers, end users, system designers, etc.). A good test framework provides good answers to many difficult questions. The area that still requires plenty of research is in finding an effective way of expressing (or even generating) test cases that are sufficiently legible for humans as well as machines.
3 GUI HAS IT ALL
In our approach, we consciously digress from the commonly accepted practice of expressing test cases in a way which is "independent" of the particular user interface. To the contrary, we concentrate on the application's interface for the following reasons:
· it is the aspect that none of the functional test automation approaches can ignore,
· it is the only common platform for discussions suitable to all parties,
· it is the primary area of interest to most expert users and test managers, and
· it is indeed suitable for expressing (functional) test cases.
Our experience has shown that by modelling the user interface we are able to express the "business cases" while preserving most of the other benefits of "business modelling" (separation of tests and scripts, increased comprehension to non-programmers, maintainability, scalability) and provide for the extremely rapid and robust test automation. The approach is particularly well-suited for applications with complex user interface focused on data maintenance. This covers a very broad range of business applications in practically all branches.
The basic objectives of our approach are:
· it must be set up quickly,
· it must rapidly evolve (new test cases must be adopted quickly),
· it must eventually scale to accommodate huge systems,
· it must be able to "live" long (maintainable over many product cycles), and
· it must be useful (test what was intended to be tested).
Our GUI-modelling idea is based on a pretty heretical hypothesis. If there is an edit field on the application's GUI, all that a functional test will do with it is to enter, retrieve/check or ignore its content. (One may argue that the field attributes (label, position, enabled/disabled, etc.) also need to be checked. This may be true. However, compared to the operations on the field's content, the operations on field's attributes are rare. For this reason, we concentrate on the content. Nevertheless, we do know how to handle both.)
The same holds true for most of the other GUI object types. For example, a push button will be pressed or ignored, a check box will be set or checked whether it is set, elements of list boxes will be selected or checked for their presence, etc. In other words, for every GUI object type there are only a few operations that need to be applied in order to perform most of the functional testing.
The first most important concept of EMOS framework is that the GUI of an application is exercised with operations in either SET-mode (enter the data in an edit field, select an item in a list box, press the button, etc.) or CHK-mode (check the content of an edit field, check the state of a radio/check button, check the existence of a list item). For this purpose our framework contains libraries of "standard wrappers" for the most commonly used object types (edit fields, static text, list boxes, all sorts of buttons, menus, toolbars, etc.). These wrappers are functions that automatically:
· determine the mode to be used,
· retrieve the test data which is to be used for the operation,
· call the appropriate native function, and
· provide the standard reporting in the test result log.
The second most important concept (they are both so important that we don't know what else to call them but "most important") is the modelling of the navigation through the application's GUI outside the test scripts. We highly discourage (apart from very few exceptions) hard-coding of any sort of information related to the user interface into the test scripts. The decisions which are all part of the test description include:
· what tab in a tab dialog to select,
· what menu item to choose,
· what entry in a tree to select,
· what button to press,
· what keyboard combinations to type.
We take into account that simple changes in the user interface might require complex changes in the test description (complex changes always require complex adaptations regardless of the concept).
The benefit of this approach is that (most of) the test scripts that need to be created need only concentrate on exercising the application's GUI. They do not (!) implement any particular test procedure (case) of any form. The instructions of what to test (what to enter, what to check, what to ignore, where to navigate to, where to come from) come from the test descriptions that reside outside the test scripts.
Why is this beneficial? First, one can start implementing the test scripts without knowing much about the concrete test cases that need to be implemented. Although we are not very proud of it but we have seen so much poor test planning and bad test organisation that we consider this to be the "normal" situation. We do try our best to influence the test practices toward something we consider better. However, if you want to survive in the jungle, you'd better get used to the trees, rain, animals, ...
Second, one can generate most of the test scripts, test data templates and the abstractions of the GUI objects. We do not yet have the statistics over the existing applications of EMOS framework but we estimate that some 60-90% of the test code can be generated simply by pointing and clicking at the application's GUI.
When we talk about the rapid test development it is these two benefits we have in mind. One can start automating as soon as there is something testable around and even then one is actually "only" clicking her/his way through. Well, it is not as simple as it may sound but it is quick.
4 THE ARCHITECTURE
There is not much difference between EMOS framework and TestFrame or similar approaches in that the test data is physically separated from the scripts. EMOS framework uses Excel® spreadsheets to store the test data. The most obvious benefit of such an approach is the high level of acceptance by non-technical personnel (test automation is difficult enough, learning yet another over-complicated tool can quickly scare even the most advanced users). Another benefit is the powerful calculation capability within the test data which greatly increases the expression power of the test cases.
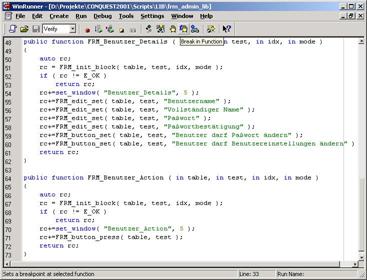
The test data is "connected" with the test scripts via the keyword concept very similar to the TestFrame's "action words". Unique names are used to identify the function which is designed to process the test data associated with the keyword. In our terminology they are called test blocks.
A typical test block contains a sequence of test primitives or atomic test units. If the test primitive corresponds to a particular GUI object, we refer to it as a physical test primitive. Otherwise it is an abstract test primitive which represents a deliberate piece of information that is made available to test scripts for any purpose. A particular test block may contain any combination of test primitives. During test execution each test block runs either in SET or CHK mode. (There are other modes available. For simplicity reasons they are not discussed in this paper. For example GEN mode generates a new test case or updates an existing test case with the information currently displayed by the application.) For physical test primitives this means that they use or verify the application respectively. Abstract test primitives deliberately interpret the test block mode.
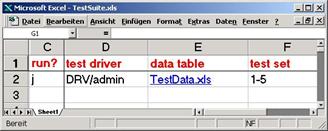
Test blocks are grouped in Excel spreadsheets or data tables. Each data table may contain many test cases. Test cases are usually organised in columns. The column-oriented format is most suitable for expressing test cases for complex GUIs that involve numerous user interface objects and complex navigation. The number of test cases is therefore limited by the number of columns (256). The number of test primitives (i.e. GUI objects involved in test) is limited by the number of rows (64k). It is however possible to organise test cases in a row-oriented structure. This is the preferred representation for simple data-driven tests (involving weakly structured test data). In this case the number of test cases is limited by the number of rows (64k) and the number of test primitives by the number of columns (256). Both representations can be freely combined since a column-oriented test case can "call" a particular or all of the row-oriented test cases and vice versa. The test automation specialist is responsible for choosing the representation that is most appropriate for the given situation. For the rest of this paper we will consider only the column-oriented test cases because they build the essence of EMOS Framework and are by far the most used ones. Each test case has the name allocated in the particular cell of the first row in the data table.
Each test case contains a single cell containing the test sequence which is a vector of test block names, links to other tests and/or a few other instructions. The test sequence defines the order in which test blocks are executed and is interpreted by the test script called the test driver. The test driver is the script that connects the data table with the test code. For each test block name the test driver calls the appropriate function or executes commands specified in the test sequence. Since test driver is the script that searches for the test sequence in a data table it can also search for anything else. We use this feature to implement the test reporting. In addition the test driver is the script responsible for loading everything else which is necessary to execute the test blocks. Our framework is tailored for WinRunner so test drivers typically load related GUI-maps and compiled modules (libraries).
Test cases are grouped into test suites. A test suite is yet another Excel table containing a sequence of test sets that need to be executed. Each test set is an instruction for executing specified test cases from the specified data table by the specified test driver. Therefore a test suite is an instruction to execute different test cases in different data tables by different test drivers. A particular test suite should, of course, group the test for a particular purpose: a complete regression suite, smoke test, sanity check, etc.
An alternative way of grouping test cases for a particular purpose is by means of test sets within TestDirector®, Mercury Interactive's test management tool.
EMOS framework is technically realised through a layered set of libraries (WinRunner terminology: compiled modules). It is packaged as WinRunner AddIn which is a plug-in component that dynamically extends the capabilities of the native product. Captured in an UML deployment diagram, the simplified architecture looks like this:

Figure 1: EMOS Framework Architecture
Due to the simple conceptual model the actual realisation tends to be very similar regardless of the system being tested (provided the naming conventions and design standards have been adhered to).
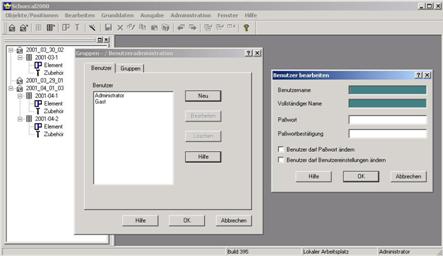
5 AN EXAMPLE
Let's see how we actually test with our framework. Please recall the two "most important" concepts we mentioned earlier and then consider the following (extremely simple) screen shots from a real-world application. Our goal is to create a few tests for the dialog for maintenance of user information (title: "Benutzer bearbeiten"). We would normally use our point-and-click wizard to generate the test code and the template for the test data. The basic modelling principles are:
· analyse the possible usage of the particular part of the application,
· identify the navigation part and decide how to model it (we probably have a pattern for it),
· select the objects of interest (test primitives),
· choose the appropriate operation for each object, and
· group the objects into some meaningful units (test blocks).
 Figure
Figure